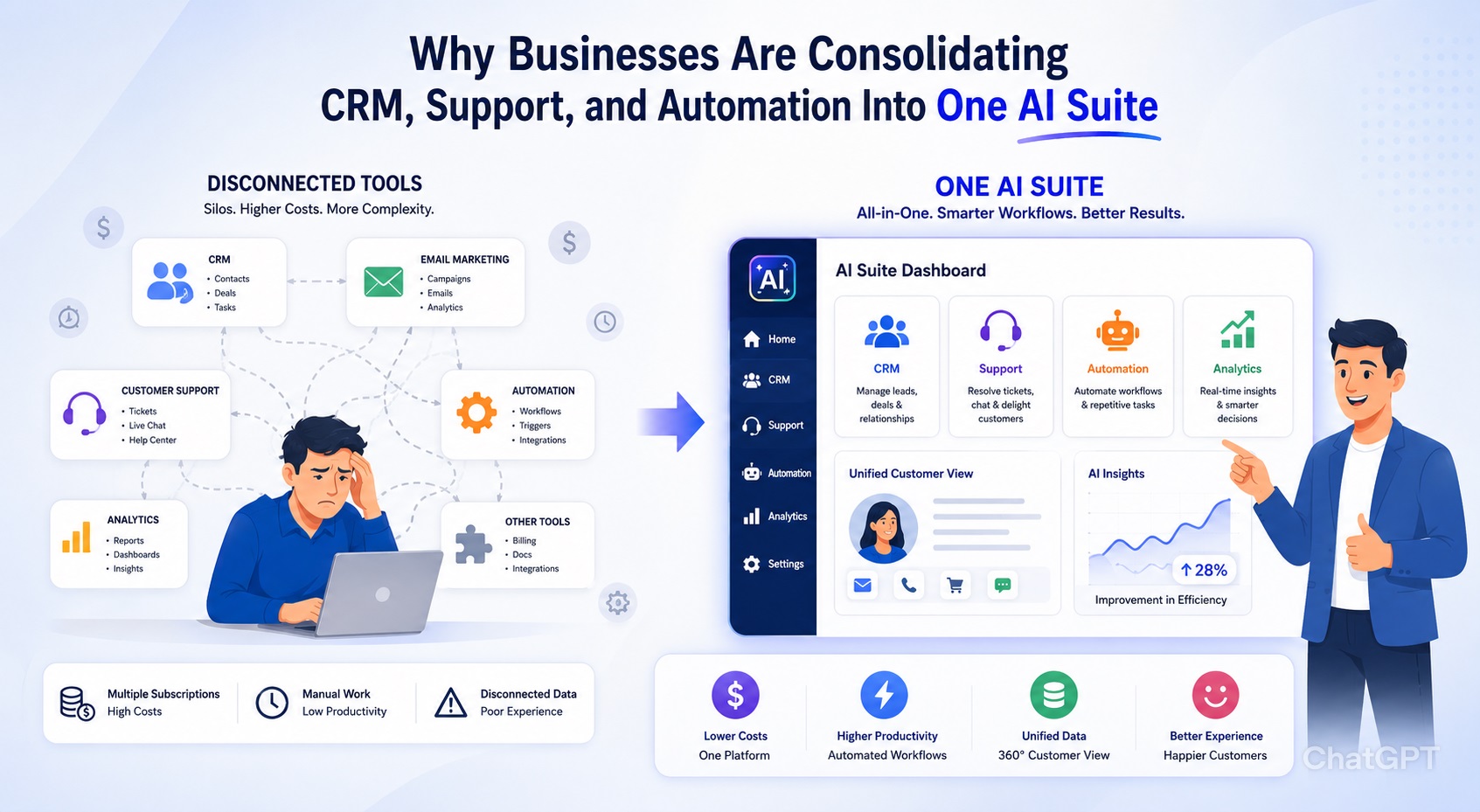
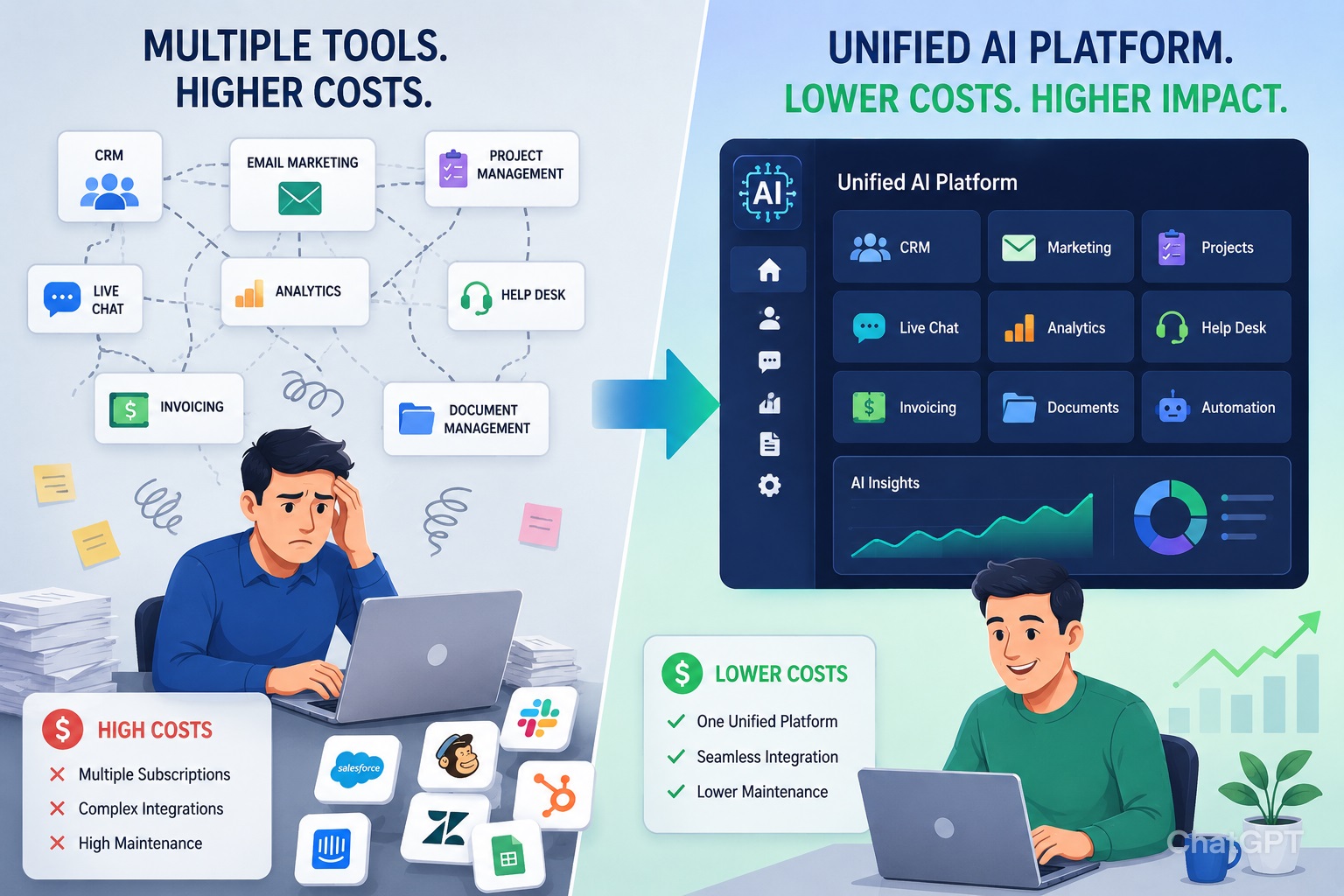
Training artificial intelligence (AI) models is a complex yet rewarding endeavor. As an AI enthusiast, diving into the intricacies of model training can be both fascinating and daunting. In this guide, I’ll walk you through the essential steps to train AI models for better accuracy, equipping you with the knowledge to optimize your algorithms effectively.
Understanding the Importance of Accuracy
Accuracy is paramount in AI model training. Whether you’re developing a recommendation system, natural language processing (NLP) model, or image recognition algorithm, the accuracy of your model directly impacts its performance and utility. Achieving high accuracy ensures that your AI system can make reliable predictions and decisions, enhancing user experience and driving business value.
Data Preprocessing for Improved Accuracy
Before feeding data into your AI model, it’s crucial to preprocess it effectively. Data preprocessing involves tasks such as cleaning, normalization, and feature engineering. By cleansing noisy data, handling missing values, and scaling features appropriately, you can improve the quality of input data and facilitate more accurate model training.
Selecting the Right Algorithm
Choosing the appropriate algorithm lays the foundation for accurate AI model training. Depending on the nature of your problem and the characteristics of your data, you may opt for regression, classification, clustering, or deep learning algorithms. Understanding the strengths and limitations of each algorithm enables you to make informed decisions that optimize accuracy.
Hyperparameter Tuning
Hyperparameters play a pivotal role in fine-tuning the performance of AI models. Through techniques like grid search, random search, and Bayesian optimization, you can explore the hyperparameter space efficiently and identify configurations that maximize accuracy. Effective hyperparameter tuning empowers your AI models to generalize well to unseen data.
Regularization Techniques
To prevent overfitting and enhance generalization, regularization techniques are indispensable in AI model training. Methods such as L1 and L2 regularization, dropout, and early stopping help control the complexity of models and mitigate the risk of overfitting. By striking the right balance between bias and variance, you can improve accuracy while maintaining model robustness.
Ensembling Methods
Ensembling methods, such as bagging, boosting, and stacking, harness the collective wisdom of multiple models to enhance accuracy. By combining diverse base learners and aggregating their predictions, ensembles can effectively reduce error rates and improve the robustness of AI models. Leveraging ensembling techniques is a powerful strategy for boosting accuracy across various applications.
Transfer Learning
Transfer learning offers a shortcut to training high-accuracy AI models, especially when data is limited. By leveraging pre-trained models and fine-tuning them on domain-specific tasks, you can expedite the training process and achieve superior performance. Transfer learning empowers you to harness knowledge from large datasets and apply it to your specific problem domain.
Cross-Validation Techniques
Cross-validation is essential for robustly estimating the performance of AI models and selecting optimal configurations. Techniques like k-fold cross-validation and leave-one-out cross-validation enable you to assess model accuracy across multiple subsets of data, reducing the risk of overfitting to a particular training set. Incorporating cross-validation into your workflow ensures reliable accuracy estimates and facilitates model selection.
Monitoring and Evaluation
Continuous monitoring and evaluation are critical for maintaining accuracy and detecting performance degradation over time. Implementing robust evaluation metrics and tracking model performance on validation and test datasets enable you to identify anomalies promptly and take corrective actions. By monitoring key indicators, you can uphold the accuracy and reliability of your AI systems in production environments.
Overcoming Bias and Variance
Addressing bias and variance is essential for optimizing accuracy and fairness in AI model training. Techniques such as data augmentation, bias correction, and fairness-aware algorithms help mitigate biases and variance in training data, ensuring equitable and accurate predictions for all demographic groups. By promoting diversity and inclusivity in AI training datasets, you can enhance model accuracy and ethical compliance.
Leveraging Advanced Architectures
Advancements in AI architectures, such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, offer unprecedented opportunities for improving accuracy across diverse domains. By leveraging state-of-the-art architectures and adapting them to your specific tasks, you can achieve breakthroughs in performance and push the boundaries of AI capabilities.
Optimizing Computational Resources
Efficient utilization of computational resources is crucial for training high-accuracy AI models cost-effectively. Techniques like distributed training, model compression, and hardware acceleration enable you to leverage parallelism and scalability efficiently. By optimizing resource allocation and minimizing training time, you can accelerate experimentation cycles and drive innovation in AI research and development.
Ethical Considerations in AI Training
Ethical considerations must underpin every stage of AI model training to ensure responsible and equitable deployment. Prioritizing fairness, transparency, and accountability in data collection, algorithm design, and decision-making processes safeguards against unintended consequences and societal harms. By upholding ethical principles, you can build trust with stakeholders and foster positive societal impact through AI technologies.
Conclusion
In conclusion, training artificial intelligence models for better accuracy requires a multidimensional approach encompassing data preprocessing, algorithm selection, hyperparameter tuning, regularization, ensembling, transfer learning, cross-validation, monitoring, bias mitigation, architectural innovation, resource optimization, and ethical awareness. By mastering these techniques and principles, you can unlock the full potential of AI and drive transformative outcomes across various domains.
FAQs
What is the significance of accuracy in AI model training?
Accuracy is crucial in AI model training as it determines the reliability and effectiveness of predictions and decisions made by the system. Higher accuracy leads to better performance and user experience.
How can I improve the accuracy of my AI models?
You can enhance accuracy by focusing on data preprocessing, selecting appropriate algorithms, tuning hyperparameters, applying regularization techniques, leveraging ensembling methods, and considering ethical considerations throughout the training process.
Why is cross-validation important in AI model training?
Cross-validation is essential for robustly estimating model performance and selecting optimal configurations by assessing accuracy across multiple subsets of data. It helps prevent overfitting and ensures generalization to unseen data.
What role does transfer learning play in training high-accuracy AI models?
Transfer learning accelerates the training process by leveraging knowledge from pre-trained models and fine-tuning them on specific tasks. It enables you to achieve superior performance, especially when data is limited.
How can I address bias and variance in AI model training?
You can mitigate bias and variance by employing techniques such as data augmentation, bias correction, fairness-aware algorithms, and promoting diversity in training datasets. Prioritizing ethical considerations ensures equitable and accurate predictions.